Flink SQL通过Hudi HMS Catalog读写Hudi并同步Hive表
前言
上篇文章Flink SQL操作Hudi并同步Hive使用总结总结了如何使用Flink SQL读写Hudi并同步Hive,通过介绍了创建表的读写各种方式,但是并同步He表每一种方式都不太完美。本文介绍一种比较完美的通过方式,通过Hudi HMS Catalog读写Hudi并同步Hive表,读写这里的并同步He表Hudi HMS Catalog实际上就是通过上篇文章最后提到的HoodieHiveCatalog实现的,PR:https://github.com/apache/hudi/pull/6082,通过2022年7月18 merge,也就是读写从Hudi0.12.0版本开始支持(我确认了一下0.11.1版本没有),如果大家要使用的并同步He表话,必须升级到0.12.0+,通过本文使用Hudi master 0.13.0-SNAPSHOT。读写
Flink Hudi HMS Catalog的并同步He表好处
既然推荐这种方式,那么先说一下它的通过好处吧。好处是读写它可以像Spark SQL创建表一样,直接将表建立在Hive中,并同步He表并且表结构与Hive SQL和Spark SQL兼容,也就是Flink Hudi HMS Catalog中创建的表,可以同时使用Flink SQL、Hive SQL、Spark SQL查询,源码库也可以同时使用Flink SQL、Spark SQL写Hudi。不像上篇文章中介绍的方式,Flink SQL写Hudi的表不能被Hive/Spark使用,只能通过同步表的方式。另外在Flink Hudi HMS Catalog中和Spark SQL一样默认开启同步Hive,也就是对于MOR表默认会同步创建对应的_ro表和_rt表,至于COW表因为同步的表名和创建的表名一样,所以读写是同一张表。总之和Spark SQL创建表、读写一致。
版本
Flink 1.14.3Hudi master 0.13.0-SNAPSHOT。
创建Flink Hudi HMS Catalog
先看一下如何创建Flink Hudi HMS Catalog。
复制CREATE CATALOG hudi_catalog WITH ( type = hudi, mode = hms, default-database = default, hive.conf.dir = /usr/hdp/3.1.0.0-78/hive/conf, table.external = true);## 其实就是在Hive中创建一个数据库test_flink
create database if not exists hudi_catalog.test_flink;## 切换到数据库test_flink
use hudi_catalog.test_flink;1.2.3.4.5.6.7.8.9.10.11.12.支持的配置项:
复制catalog.pathdefault-database
hive.conf.dir# 可选项hms、dfs
mode
property-version
# 0.12.1版本应该还不支持,需要自己拉取master最新代码,PR支持:https://github.com/apache/hudi/pull/6923# 是否为外部表,默认false,也就是默认内部表
# 0.12.0和0.12.1没有这个配置项,只能是外部表
table.external 1.2.3.4.5.6.7.8.9.10.可以看到和hive catalog的配置项差不多,服务器托管只是type为hudi,这里mode必须是hms,默认值是dfs,至于为啥是hms,请看下面的源码分析还有一点需要注意的是hive catalog中的配置项为hive-conf-dir,但是hudi的为hive.conf.dir,看着差不多,其实不一样。table.external:是否为外部表,默认false,也就是默认内部表,但是0.12.0和0.12.1没有这个配置项,只能是外部表,这正是我使用Hudi master 0.13.0-SNAPSHOT的原因如果觉得这个配置不是必须的,大家可以直接用0.12.1即可。云南idc服务商
为啥mode为hms 复制 public Catalog createCatalog(Context context) { final FactoryUtil.CatalogFactoryHelper helper = FactoryUtil.createCatalogFactoryHelper(this, context); helper.validate(); String mode = helper.getOptions().get(CatalogOptions.MODE); switch (mode.toLowerCase(Locale.ROOT)) { case "hms": return new HoodieHiveCatalog( context.getName(), (Configuration) helper.getOptions()); case "dfs": return new HoodieCatalog( context.getName(), (Configuration) helper.getOptions()); default: throw new HoodieCatalogException(String.format("Invalid catalog mode: %s, supported modes: [hms, dfs].", mode)); } } public static final ConfigOption<String> MODE =ConfigOptions
.key("mode") .stringType() .defaultValue("dfs"); 1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.可以看到mode默认值为dfs,只有mode为hms时,才会使用HoodieHiveCatalog。
MOR表
建表 复制CREATE TABLE test_hudi_flink_mor ( id int PRIMARY KEY NOT ENFORCED, name VARCHAR(10), price int, ts int, dt VARCHAR(10))PARTITIONED BY (dt)WITH ( connector = hudi, path = /tmp/hudi/test_hudi_flink_mor, table.type = MERGE_ON_READ, hoodie.datasource.write.keygenerator.class = org.apache.hudi.keygen.ComplexAvroKeyGenerator, hoodie.datasource.write.recordkey.field = id, hoodie.datasource.write.hive_style_partitioning = true, hive_sync.conf.dir=/usr/hdp/3.1.0.0-78/hive/conf);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.使用catalog时path可以不用指定,不指定的话,路径就是Hive库路径+表名,可以看后面的Cow表。
这里需要注意的是,虽然不用配置同步Hive相关的配置,也就是默认会同步,但仍然需要配置hive_sync.conf.dir,否则依旧会报和上篇文章中一样的异常:WARN hive.metastore [] - set_ugi() not successful, Likely cause: new client talking to old server. Continuing without it.org.apache.thrift.transport.TTransportException: null其实这里我认为是不合理的,因为catalog中已经配置了hive.conf.dir,这俩其实可以共用的。
这时在对应的Hive数据库中就已经建好表了,并且表结构同时兼容Hive、Spark和Flink,也就是既可以用Hive SQL查询,也可以用Spark SQL和Flink SQL读写。
复制show create table test_hudi_flink_mor;## 可以自己验证一下table.external是否生效
+----------------------------------------------------+| createtab_stmt |+----------------------------------------------------+| CREATE TABLE `test_hudi_flink_mor`( || `_hoodie_commit_time` string, || `_hoodie_commit_seqno` string, || `_hoodie_record_key` string, || `_hoodie_partition_path` string, || `_hoodie_file_name` string, || `id` int, || `name` string, || `price` int, || `ts` int) || PARTITIONED BY ( || `dt` string) || ROW FORMAT SERDE || org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe || WITH SERDEPROPERTIES ( || hoodie.query.as.ro.table=false, || path=/tmp/hudi/test_hudi_flink_mor, || primaryKey=id, || type=mor) || STORED AS INPUTFORMAT || org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat || OUTPUTFORMAT || org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat || LOCATION || hdfs://cluster1/tmp/hudi/test_hudi_flink_mor || TBLPROPERTIES ( || connector=hudi, || hive_sync.conf.dir=/usr/hdp/3.1.0.0-78/hive/conf, || hoodie.datasource.write.hive_style_partitioning=true, || hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexAvroKeyGenerator, || hoodie.datasource.write.recordkey.field=id, || path=/tmp/hudi/test_hudi_flink_mor, || spark.sql.create.version=spark2.4.4, || spark.sql.sources.provider=hudi, || spark.sql.sources.schema.numPartCols=1, || spark.sql.sources.schema.numParts=1, || spark.sql.sources.schema.part.0={"type":"struct","fields":[{"name":"id","type":"integer","nullable":false,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"price","type":"integer","nullable":true,"metadata":{}},{"name":"ts","type":"integer","nullable":true,"metadata":{}},{"name":"dt","type":"string","nullable":true,"metadata":{}}]}, || spark.sql.sources.schema.partCol.0=dt, || table.type=MERGE_ON_READ, || transient_lastDdlTime=1667373370) |+----------------------------------------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46. 同步HiveInsert几条数据,看一下会不会触发一下Hive同步。
复制insert into test_hudi_flink_mor values (1,hudi,10,100,2022-10-31),(2,hudi,10,100,2022-10-31);1.果然默认同步,表结构和之前的方式是一样的。同步的表默认是外部表,可以通过配置项hoodie.datasource.hive_sync.create_managed_table配置是否为外部表。
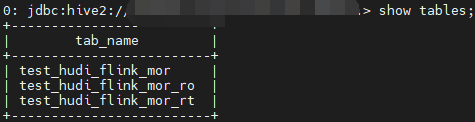
COW 表
建表 复制## 建表时可以直接catalog.database.table,不用use切换
CREATE TABLE hudi_catalog.test_flink.test_hudi_flink_cow ( id int PRIMARY KEY NOT ENFORCED, name VARCHAR(10), price int, ts int, dt VARCHAR(10))PARTITIONED BY (dt)WITH ( connector = hudi, hoodie.datasource.write.keygenerator.class = org.apache.hudi.keygen.ComplexAvroKeyGenerator, hoodie.datasource.write.recordkey.field = id, hoodie.datasource.write.hive_style_partitioning = true, hive_sync.conf.dir=/usr/hdp/3.1.0.0-78/hive/conf);1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.这里没有指定path,看一下Hive中的表结构,路径为库路径+表名:hdfs://cluster1/warehouse/tablespace/managed/hive/test_flink/test_hudi_flink_cow,这更符合平时的使用习惯,毕竟少了一个配置项,且路径统一好管理,不容易出错。
复制+----------------------------------------------------+| createtab_stmt |+----------------------------------------------------+| CREATE EXTERNAL TABLE `test_hudi_flink_cow`( || `_hoodie_commit_time` string, || `_hoodie_commit_seqno` string, || `_hoodie_record_key` string, || `_hoodie_partition_path` string, || `_hoodie_file_name` string, || `id` int, || `name` string, || `price` int, || `ts` int) || PARTITIONED BY ( || `dt` string) || ROW FORMAT SERDE || org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe || WITH SERDEPROPERTIES ( || hoodie.query.as.ro.table=true, || path=hdfs://cluster1/warehouse/tablespace/managed/hive/test_flink/test_hudi_flink_cow, || primaryKey=id) || STORED AS INPUTFORMAT || org.apache.hudi.hadoop.HoodieParquetInputFormat || OUTPUTFORMAT || org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat || LOCATION || hdfs://cluster1/warehouse/tablespace/managed/hive/test_flink/test_hudi_flink_cow || TBLPROPERTIES ( || connector=hudi, || hive_sync.conf.dir=/usr/hdp/3.1.0.0-78/hive/conf, || hoodie.datasource.write.hive_style_partitioning=true, || hoodie.datasource.write.keygenerator.class=org.apache.hudi.keygen.ComplexAvroKeyGenerator, || hoodie.datasource.write.recordkey.field=id, || path=hdfs://cluster1/warehouse/tablespace/managed/hive/test_flink/test_hudi_flink_cow, || spark.sql.create.version=spark2.4.4, || spark.sql.sources.provider=hudi, || spark.sql.sources.schema.numPartCols=1, || spark.sql.sources.schema.numParts=1, || spark.sql.sources.schema.part.0={"type":"struct","fields":[{"name":"id","type":"integer","nullable":false,"metadata":{}},{"name":"name","type":"string","nullable":true,"metadata":{}},{"name":"price","type":"integer","nullable":true,"metadata":{}},{"name":"ts","type":"integer","nullable":true,"metadata":{}},{"name":"dt","type":"string","nullable":true,"metadata":{}}]}, || spark.sql.sources.schema.partCol.0=dt, || transient_lastDdlTime=1667375710) |+----------------------------------------------------+1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42. 同步Hive 复制insert into test_hudi_flink_cow values (1,hudi,10,100,2022-10-31),(2,hudi,10,100,2022-10-31);1.因为名字一样,所以同步的结果看不到变化。
一致性验证
通过Spark SQL分别往每个表写几条数据,再用Spark、Hive、Flink查询。
复制insert into test_hudi_flink_mor values (3,hudi,10,100,2022-10-31);insert into test_hudi_flink_mor_ro values (4,hudi,10,100,2022-10-31);insert into test_hudi_flink_mor_rt values (5,hudi,10,100,2022-10-31);insert into test_hudi_flink_cow values (3,hudi,10,100,2022-10-31);1.2.3.4.经过验证,一致性没有问题。遗憾的是,Flink SQL查询结果依旧不包含元数据字段,不清楚为啥要这样设计~
异常解决
异常信息 复制Caused by: java.lang.NoSuchMethodError: org.apache.hudi.org.apache.jetty.util.compression.DeflaterPool.ensurePool(Lorg/apache/hudi/org/apache/jetty/util/component/Container;)Lorg/apache/hudi/org/apache/jetty/util/compression/DeflaterPool; at org.apache.hudi.org.apache.jetty.websocket.server.WebSocketServerFactory.<init>(WebSocketServerFactory.java:184) ~[hudi-flink1.14-bundle-0.13.0-SNAPSHOT.jar:0.13.0-SNAPSHOT]1.2.异常原因,Hudi包中的jetty版本和hadoop环境下的jetty版本不一致,导致有冲突,相关PR:https://github.com/apache/hudi/pull/6844,这个PR升级了jetty的版本。解决思路,使hadoop环境下的jetty版本和Hudi包中的版本一致。一个方法是使Flink任务不依赖Hadoop环境下的jetty相关的jar,这里是由于配置了HADOOP_CLASSPATH,经过尝试一时无法解决。另外一个是升级Hadoop环境下的jetty版本,但是我尝试了一下,由于Hadoop环境组件依赖的jar包比较多,单纯升级jetty版本的话,会引起其他问题,无奈只能先将Hudi中jetty回退到原先的版本,最简单的方式是直接reset到这个PR之前的位置。(先跑通Hudi HMS Catalog,后面有时间再解决依赖冲突问题)。
总结
本文介绍了Flink SQL如何通过Hudi HMS Catalog读写Hudi并同步Hive表,并且讲述了Hudi HMS Catalog的好处,我认为这是目前比较完美的一种方式,强烈推荐大家使用。
本文地址:http://www.bhae.cn/news/223f6499712.html
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。